Yolov7 정리
Architecture
1. Extended efficient layer aggregation networks

VovNet → CSPVoVNet
- The gradient analysis approach described above makes inferences faster and more accurate
CSPVoVNet → ELAN
- By controlling the shortest longest gradient path, a deeper network can learn and converge effectively
ELAN → E-ELAN
- E-ELAN uses expand, shuffle, merge
cardinality*to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path.
- to use group convolution to expand the channel and cardinality of computational blocks.
- the number of channels in each group of feature map will be the same as the number of channels in the original architecture
- E-ELAN can also guide different groups of computational blocks to learn more diverse features.
2. Model scaling for concatenation-based models

- we will find that when scaling up or scaling down is performed on depth, the in-degree of a translation layer which is immediately after a concatenation-based computational block will decrease or increase
- When we scale the depth factor of a computational block, we must also calculate the change of the output channel of that block. Then, we will perform width factor scaling with the same amount of change on the transition layers
- Our proposed compound scaling method can maintain the properties that the model had at the initial design and maintains the optimal structure.
- width와 depth를 따로 scaling 했을 때 독립적인 영향력을 보고 싶은데, depth를 늘리면 width가 늘어나는 현상떄문에 c의 모델링을 채택
Trainable bag-of-freebies*
1. planned re-parameterized convolution

RepConvactually combines 3 × 3 convolution, 1 × 1 convolution, and identity connection in one convolutional layer.
- we find that the identity connection in RepConv destroys the residual in ResNet and the concatenation in DenseNet, which provides more diversity of gradients for different feature maps. For the above reasons, we use RepConv without identity connection (
RepConvN) to design the architecture of planned re-parameterized convolution.
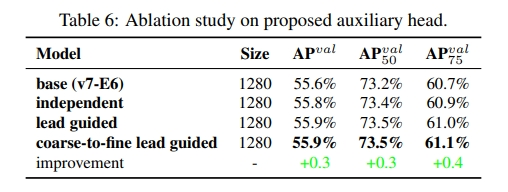
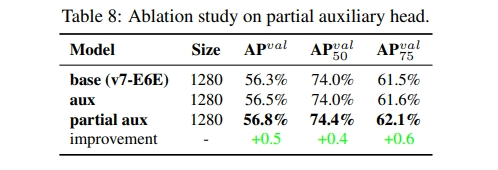
2. Coarse for auxiliary and fine for lead loss

- Its main concept is to add extra auxiliary head in the middle layers of the network, and the shallow network weights with assistant loss as the guide
Lead head guided label assigner
- This set of soft labels will be used as the target training model for both auxiliary head and lead head
- By letting the shallower auxiliary head directly learn the information that lead head has learned, lead head will be more able to focus on learning residual information that has not yet been learned
Coarse-to-fine lead head guided label assigner
- the predicted result of the lead head and the ground truth to generate soft label
- fine label is the same as the soft label generated by lead head guided label assigner, and coarse label is generated by allowing more grids to be treated as positive target by relaxing the constraints of the positive sample assignment process
- The mechanism mentioned above allows the importance of fine label and coarse label to be dynamically adjusted during the learning process, and makes the optimizable upper bound of fine label always higher than coarse label.
3. Other trainable bag-of-freebies
3-1. Batch normalization in conv-bn-activation topology
This part mainly connects batch normalization layer directly to convolutional layer. The purpose of this is to integrate the mean and variance of batch normalization into the bias and weight of convolutional layer at the inference stage.
3-2. Implicit knowledge in YOLOR combined with convolution feature map in addition and multiplication manner
Implicit knowledge in YOLOR can be simplified to a vector by pre-computing at the inference stage. This vector can be combined with the bias and weight of the previous or subsequent convolutional layer.
3-3. EMA model
EMA is a technique used in mean teacher, and in our system we use EMA model purely as the final inference model.
Experiements
Proposed compound scaling method

Proposed planned re-parameterized model
Proposed assistant loss for auxiliary head


용어
cardinality
- 똑같은 형태의 빌딩 블록의 갯수 (the size of the set of transformations)
- 네트워크의 층이 깊어지거나(deeper) 넓어지는(wider) 것보다 정확도를 얻는 것에 더 효과적이다.
bag of freebies
- inference 비용을 늘리지 않고 정확도를 향상시키는 방법
- bag of specials : inference 비용을 조금 높이고 정확도를 크게 향상시키는 방법

deep supervision
"The advantage of such deep supervision is evident: (1)for small training data and relatively shallower networks, deep supervision functions as a strong “regularization” for classification accuracy and learned features; (2) for large training data and deeper networks deep supervision makes it convenient to exploit the significant performance gains that extremely deep networks can bring by improving otherwise problematic convergence behavior”
transition layer
- feature map의 가로, 세로 사이즈를 줄여주고 feature map의 개수를 줄여주는 역할
Batch Normalization,ReLU,1x1 convolution,2x2 average pooling으로 구성
- transition layer를 통과하면 feature map의 개수(channel)이 절반으로 줄어들고,
2x2 average pooling를 통해 feature map의 가로 세로 크기 또한 절반으로 줄어듦 (theta = 0.5)
Uploaded by
N2T