
※ EMP 테이블 구조

※ 리포팅 함수
| rollup | cube | grouping |
1. rollup
|
# 문제 74. 직업, 직업별 총 월급을 출력하는데, 총월급이 맨 아래 출력되게 하시오. 
select job, sum(sal) from emp group by rollup(job); |
|
- group by의 rollup함수를 쓰면 저렇게 sum의 경우에는 모든 그룹의 총 합이 나온다. max, min, count의 경우에도 한번 해보면 도움이 될다.
select job, sum(sal), max(sal), min(sal), count(*) from emp group by rollup(job) |
|
- 보통 생각하기 귀찮을 때 union all을 사용해서 저런 형식을 만드려고 하는 데 이는 SQL 초보가 하는 것이다. 위의 예제를 union으로 만든다면
select job, sum(sal) as "sum(sal)"
- 이렇게 표현할 수 있다. 하지만 union의 경우에 데이터가 맣은 경우에 매우 느려지기 때문에 가급적 리포팅 함수를 익히자. |
2. cube 함수
|
# 문제 75. 아래와 같이 출력되게 하시오. 
select job, sum(sal) from emp group by cube(job); |
3. grouping sets 함수 ~ 응용 최고 함수
|
# 예시 각 부서와 직업별로 월급의 총합을 출력하시오. 
select deptno, job, sum(sal) from emp group by grouping sets((deptno,job), (deptno), ()); |
|
- 해석 : deptno와 job을 묶어서 각각의 월급 총합을 구한다. 원래라면 3X5 = 15개의 경우의 수가 있지만 예를 들어 deptno=10 의 경우에는 SALESMAN과 ANALYST가 없는 경우가 있으니 저렇게 9가지 경우가 나온다. 다음은 deptno를 그룹화 시켰는데 10,20,30 부서의 월급 총합이 구해지고 마지막 ()의 경우에는 모든 월급의 총합을 구해준다. |
|
# 문제 76. 부서와 직업별 월급 합을 출력하시오. 
select deptno, job, sum(sal) from emp group by grouping sets((deptno,job)) order by deptno; |
|
# 문제 77. 위의 결과에서 월급 총합을 맨아래 출력되게 하시오. 
select deptno, job, sum(sal) from emp group by grouping sets((deptno,job),()) order by deptno; |
|
# 문제 78. 76번에서 부서별 월급 총합을 출력하시오. 
select deptno, job, sum(sal) from emp group by grouping sets((deptno,job),(deptno)) order by deptno; |
|
# 문제 79. 다음 쿼리를 튜닝하시오.  select deptno, job, sum(sal) as "sum(sal)"
방법 1. select deptno, job, sum(sal) from emp group by grouping sets((deptno,job),(deptno),()) order by deptno, job;
방법 2. select deptno, job, sum(sal) from emp group by rollup(deptno, job) order by deptno, job; |
|
- 추가 : order by를 안써도 무방하다면 가급적 쓰지는 말자. 속도가 느려지는 원인이다. |
※ grouping sets과 rollup의 매커니즘
|
- rollup 매커니즘을 grouping sets으로 표현한다면?? rollup(deptno, job, mgr) = group : (deptno, job, mgr) group : (deptno, job) group : (deptno) group : ()
- 쿼리 예시 select deptno, job, sum(sal) from emp group by rollup(deptno, job)
=
select deptno, job, sum(sal) from emp group by grouping sets((deptno,job),(deptno),()); |
|
# (어려움) 문제 80. dept 테이블과 JOIN하여 같이 출력하시오. <'토탈값' 이란 글자가 나오게 하시오.>  
select nvl(job,'토탈값') as job, count( decode(d.loc, 'NEW YORK', 1, null)) as "NEW YORK", count( decode(d.loc, 'DALLAS', 1, null)) as "DALLAS", count( decode(d.loc, 'CHICAGO', 1, null)) as "CHICAGO", count( decode(d.loc, 'BOSTON', 1, null)) as "BOSTON" from emp e, dept d where e.deptno = d.deptno group by rollup(job); |
|
- group을 job으로 하고 dept 테이블의 loc를 사용해서 숫자를 세고 있다. decode를 사용해서 해당 컬럼이 맞으면 1을 아니면 null을 줘서 숫자를 센다. (0을 주면 시간이 더 걸린다. 값은 동일) |
|
# (어려움) 문제 81. 다음 결과를 출력하는데 decode를 사용하지 않고 pivot을 사용하여 출력하시오. 
select nvl(job,'total') as job, to_char(nvl(sum("10"),0),'999,999') as "10", to_char(nvl(sum("20"),0),'999,999') as "20", to_char(nvl(sum("30"),0),'999,999') as "30", to_char(nvl(sum("10"),0)+nvl(sum("20"),0)+nvl(sum("30"),0),'999,999') as total from (select job, deptno, sal from emp) pivot(sum(sal) for deptno in (10,20,30)) group by rollup(job) order by job asc; |
|
# 순서 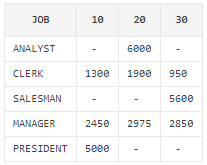    select *
select nvl(job,'total') as job
select to_char(nvl(sum("10"),0),'999,999') as "10",
select nvl(job,'total') as job, to_char(nvl(sum("10"),0),'999,999') as "10", to_char(nvl(sum("20"),0),'999,999') as "20", to_char(nvl(sum("30"),0),'999,999') as "30", to_char(nvl(sum("10"),0)+nvl(sum("20"),0)+nvl(sum("30"),0),'999,999') as total from (select job, deptno, sal from emp) pivot(sum(sal) for deptno in (10,20,30)) group by rollup(job) order by job asc; |
'Itwill 학습내용 정리 > 1. SQL' 카테고리의 다른 글
| 6.1 JOIN ~ Oracle 버전 (0) | 2019.04.25 |
|---|---|
| 5. 데이터 분석 함수 (0) | 2019.04.25 |
| 3. 그룹함수 (0) | 2019.04.18 |
| 2.5 (단일행 함수) 일반 함수 & pivot 사용법 (0) | 2019.04.18 |
| 2.4 (단일행 함수) 변환 함수 (0) | 2019.04.18 |